This article is translated to English using GPT-3.5 and polished by the author. This is the original post.
For some complex obfuscation techniques, control flow analysis is necessary to restore them. This article introduces the basic knowledge of .NET control flow analysis. Understanding these is enough to restore most obfuscations that require control flow analysis.
Introduction
The new year has begun, and last year’s articles should only be considered basic. This year, we will study the difficult ones. In my opinion, the three most difficult protections under .NET are:
IL-level virtual machine
Control flow obfuscation
Jit Hook
If any of these protections are not removed, they will greatly hinder our analysis of an assembly using dnSpy.
Today, let’s briefly delve into one of the difficulties I think: “control flow”. The prerequisite for entering control flow analysis is that you need to have a certain understanding of IL. If you understand it, then congratulations. For some simple control flow obfuscations, you can write your own deobfuscation tool. If you don’t understand it, it doesn’t matter either. This takes time to learn, and I also spent some time researching it myself. When reading this article, you must not just skim through it. You must open Visual Studio, write code yourself, and follow the article step by step.
The purpose of my previous control flow analysis project was to learn control flow and understand the lowest-level implementation and principles. Although there are ready-made projects like 0xd4d’s de4dot.blocks (the author of dnSpy), de4dot is open-source under the GPLv3 license, and the project itself is no longer maintained. Moreover, there are not many comments in the project. If there are any bugs, they can only be fixed by yourself. It is better to write a project from scratch if you have time to understand what others have written and what they mean.
Control flow is a very abstract thing, and I’m not particularly familiar with the graphics libraries. Therefore, we use the most brute-force and simplest method to convert all control flows into string information for debugging. I remember that a fellow student in one of my previous posts hoped for a video explanation. Since the explanation of the control flow cannot be explained clearly in a few lines of text, I will record a video to supplement the things that cannot be explained in the article. This morning, I learned about flowchart libraries, and there is code to draw the control flow at the end of the article!!!
I don’t know if you noticed it, but the article title has a “(I)”. Because this thing is quite complicated, it is tiring to write and also tiring to read after finishing one article. So if there is time, there may be “(II)”, “(III)” and so on.
This article is only an introduction and will not involve any control flow obfuscation. We only need to build a framework that can analyze the control flow, represent the control flow, and feedback the analyzed and processed results to the method body.
The entire project code is relatively large, with more than 2k+ lines of code when empty lines, comments, and lines with only one symbol are counted. Therefore, only the key code will be mentioned below, and the remaining code can be downloaded in the attachment. The code in the attachment is complete and can be added directly to a new project.
Reminder: The structures defined in the article are slightly different from those in de4dot.blocks, but the ideas are similar.
Building a good framework is like building a house. We need to define a structure that can convert the linear instruction stream, exception handling clauses, and local variables in the method body into a structure that is easier to analyze without loss.
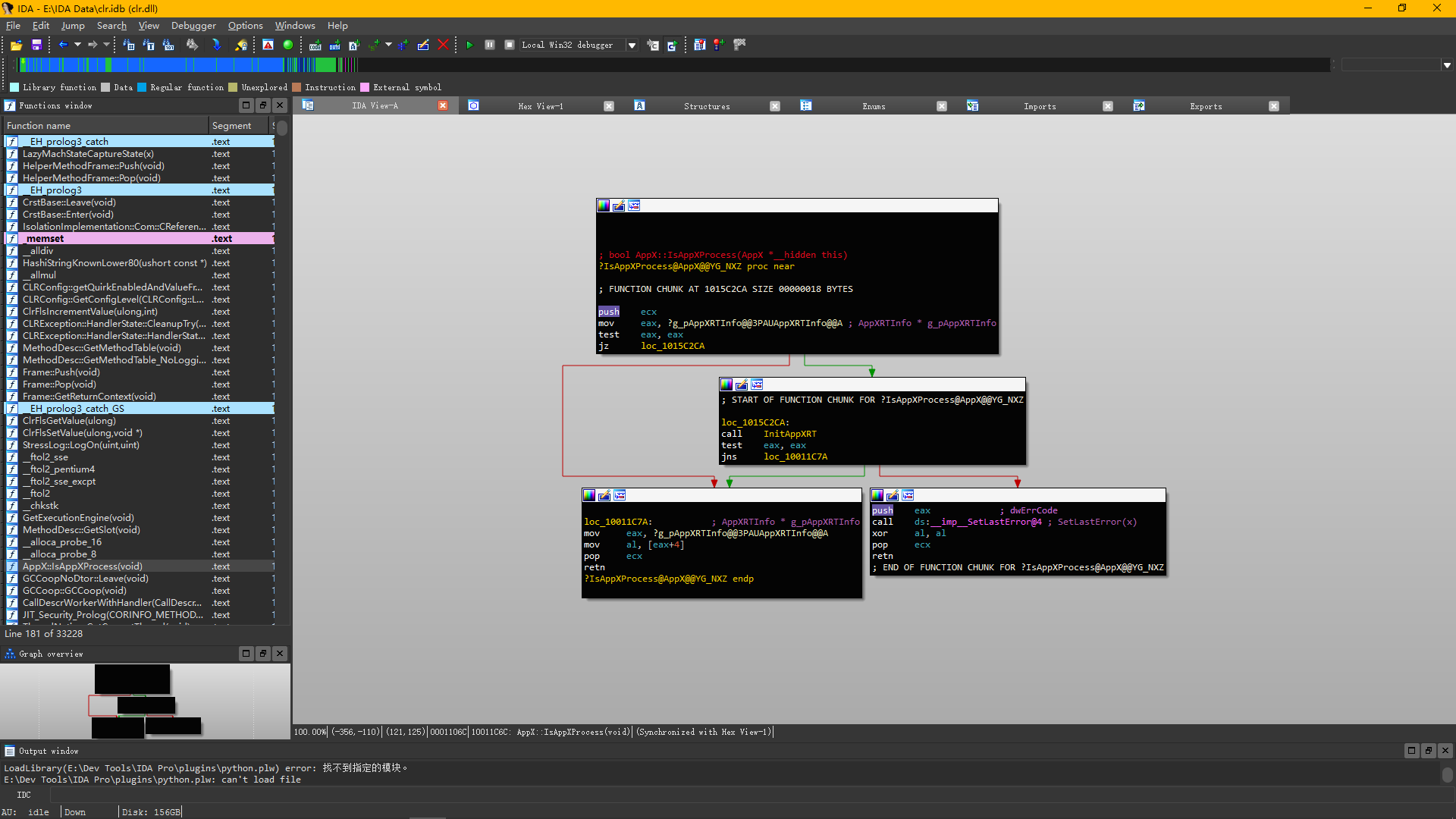
For example, IDA truncates before jumping, becoming a code snippet that we can refer to as a “Block.” We can convert a method body into many blocks using various jump statements.
Of course, things are not that simple. Let’s return to .NET and see that it has exception handling clauses.
Take the two red boxes in the figure as an example. The first one is “try,” and the second one is “catch.” If the execution of “try” is normal, we won’t go into “catch.” Therefore, we also need to rely on exception handling clauses to partition the method body into blocks.
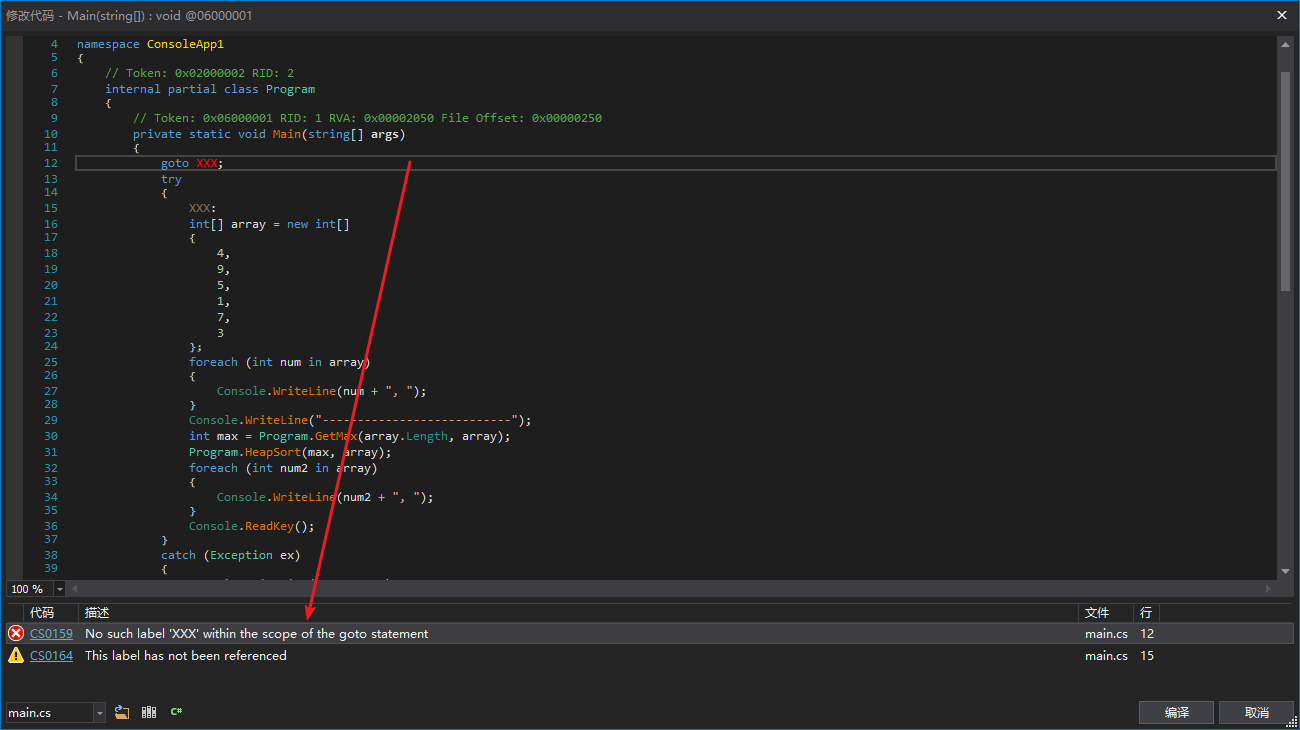
Does this mean we’re done? Definitely not. A “try” or a “catch” can be called a scope. We can jump from a smaller sub-scope to a larger parent scope, but we cannot jump from a larger parent scope to a smaller sub-scope.
The code in the first figure is illegal, while the code in the second figure is legal.
From the IL perspective, we can only jump to the first statement of a scope, not to any other statement in the scope. What does that mean?
The “br” in the first figure jumps to the second statement of the “try” block, making it illegal.
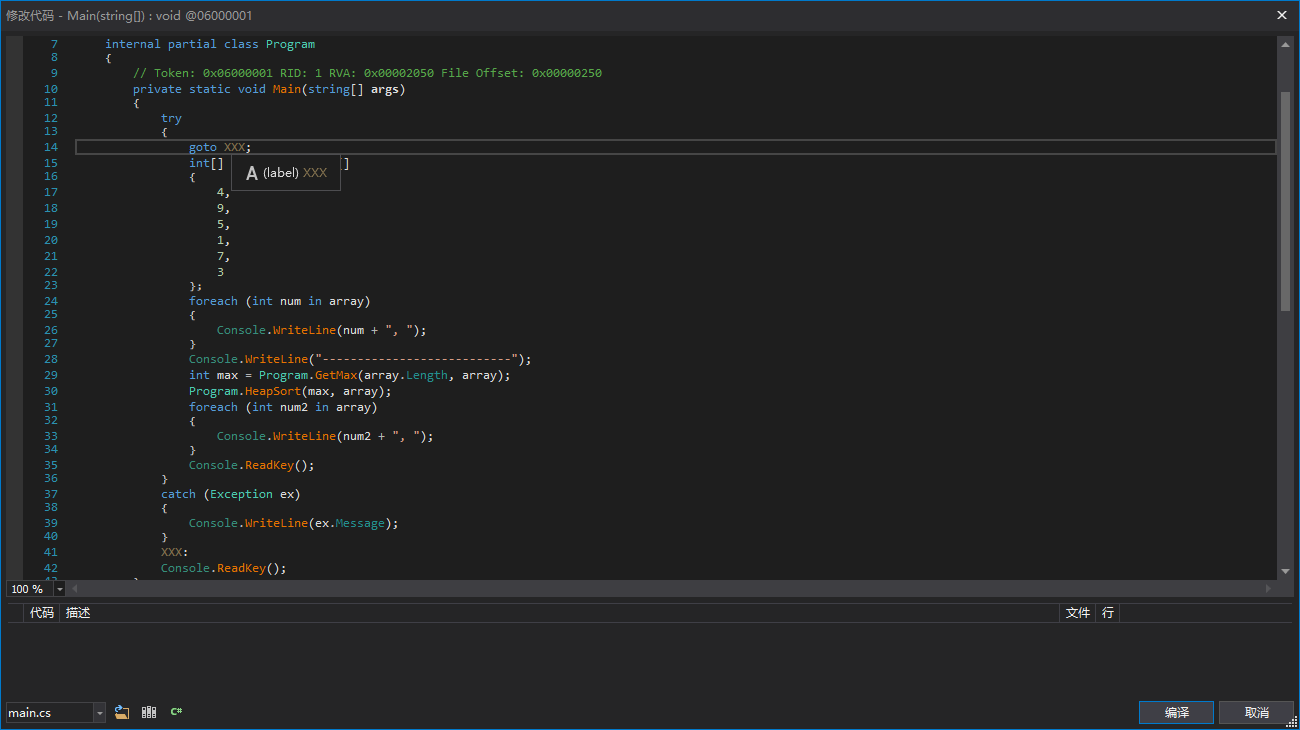
How do we leave the “try” block? By using the “leave“ instruction.
In C#, to prevent such situations from happening, we have “larger scopes cannot enter smaller scopes, but smaller scopes can enter larger scopes.”
The catch block is not directly referenced by any jump instruction; it is only entered if an exception occurs within the try block.
So, we can define the structure as follows (some code is omitted):
publicenum ScopeBlockType { Normal, Try, Filter, Catch, Finally, Fault } publicinterfaceIBlock { IBlock Scope { get; set; } bool HasExtraData { get; } voidPushExtraData(object obj); voidPopExtraData(); T PeekExtraData<T>(); } publicabstractclassBlockBase : IBlock { private IBlock _scope; private Stack<object> _extraDataStack; public IBlock Scope { get => _scope; set => _scope = value; } publicbool HasExtraData => _extraDataStack != null && _extraDataStack.Count != 0; public T PeekExtraData<T>() { return (T)_extraDataStack.Peek(); } publicvoidPopExtraData() { _extraDataStack.Pop(); } publicvoidPushExtraData(object obj) { if (_extraDataStack == null) _extraDataStack = new Stack<object>(); _extraDataStack.Push(obj); } } publicsealedclassBasicBlock : BlockBase { private List<Instruction> _instructions; private OpCode _branchOpcode; private BasicBlock _fallThrough; private BasicBlock _conditionalTarget; private List<BasicBlock> _switchTargets; public List<Instruction> Instructions { get => _instructions; set => _instructions = value; } publicbool IsEmpty => _instructions.Count == 0; public OpCode BranchOpcode { get => _branchOpcode; set => _branchOpcode = value; } public BasicBlock FallThrough { get => _fallThrough; set => _fallThrough = value; } public BasicBlock ConditionalTarget { get => _conditionalTarget; set => _conditionalTarget = value; } public List<BasicBlock> SwitchTargets { get => _switchTargets; set => _switchTargets = value; } } publicabstractclassScopeBlock : BlockBase { protected List<IBlock> _blocks; protected ScopeBlockType _type; public List<IBlock> Blocks { get => _blocks; set => _blocks = value; } public IBlock FirstBlock { get => _blocks[0]; set => _blocks[0] = value; } public IBlock LastBlock { get => _blocks[_blocks.Count - 1]; set => _blocks[_blocks.Count - 1] = value; } public ScopeBlockType Type { get => _type; set => _type = value; } } publicsealedclassTryBlock : ScopeBlock { privatereadonly List<ScopeBlock> _handlers; public List<ScopeBlock> Handlers => _handlers; } publicsealedclassFilterBlock : ScopeBlock { private HandlerBlock _handler; public HandlerBlock Handler { get => _handler; set => _handler = value; } } publicsealedclassHandlerBlock : ScopeBlock { private ITypeDefOrRef _catchType; public ITypeDefOrRef CatchType { get => _catchType; set => _catchType = value; } } publicsealedclassMethodBlock : ScopeBlock { private List<Local> _variables; public List<Local> Variables { get => _variables; set => _variables = value; } }
I will explain this definition. Here, there is a strange BlockBase and an ExtraData, which can be understood as additional data. Sometimes when we analyze control flow, we need to bind a piece of data with a block. This is where ExtraData comes in handy. Since there may be many pieces of data that need to be bound, we use a Stack<T>, which is a stack type that follows the Last-In-First-Out (LIFO) principle. We can push the data during initialization and then peek when we need it. After using it, we can pop it.
BasicBlock is the smallest unit and is called a basic block. For convenience, if the last instruction in a basic block changes the control flow, we delete it and assign it to the _branchOpcode field. Then, we assign the jump target to _fallThrough, _conditionalTarget, and _switchTargets fields. This makes it much easier to update the jump relationships between control flows.
Many basic blocks together can form a scope block, which is a ScopeBlock. Of course, ScopeBlocks can also be nested within each other, such as one ScopeBlock containing another ScopeBlock.
Instruction Stream to Blocks
The blocks mentioned in the subheading refer to the structures we defined earlier, such as BasicBlock.
Returning to the disassembled control flow graph displayed in IDA, we can see that the control flow is actually a directed graph.
This directed graph may have cycles, self-loops, and a point may connect to many points. We can process it using some ideas from “graph” theory (which is not difficult, search for BFS, DFS, directed graphs, and understand these 3 things).
Let’s add a class called “BlockParser” and add the following code:
privatestaticboolHasNotSupportedInstruction(IEnumerable<Instruction> instructions) { foreach (Instruction instruction in instructions) switch (instruction.OpCode.Code) { case Code.Jmp: returntrue; } returnfalse; } }
We don’t need to handle the jmp instruction because it is very complicated to deal with, and it does not appear in normal .NET programs. If you want to learn about jmp, you can refer to Microsoft Docs. Note that the IL jmp is not the same as assembly jmp.
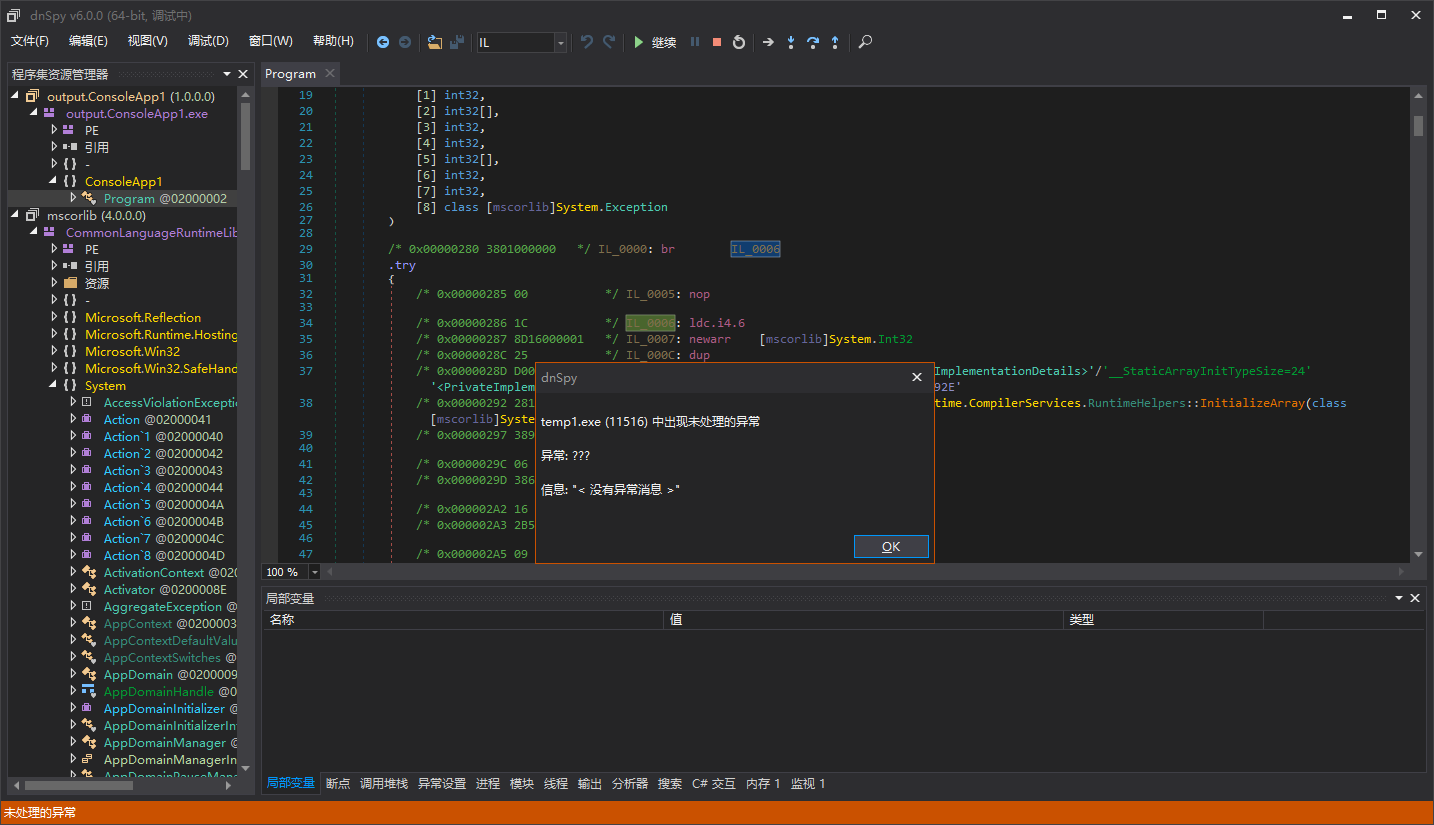
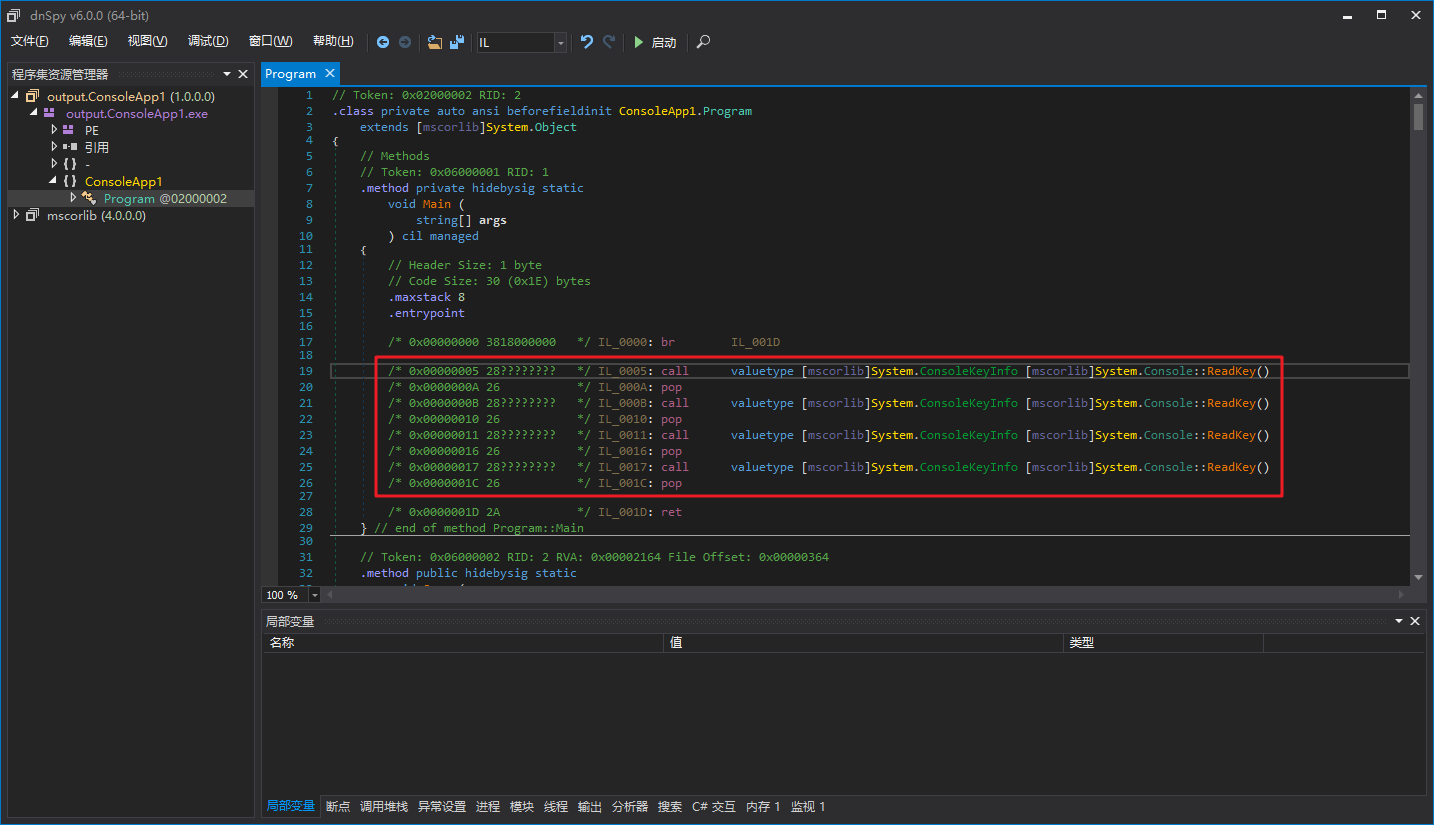
First of all, we need to analyze potential entry points. Why do we say “potential”? Because the method body may be obfuscated, filled with many instructions that cannot be executed, like this:
The red box is a basic block that will never be used, although the first statement in the red box at IL_0005 is indeed an entry point.
_isEntrys indicates whether a certain instruction is a potential entry point. If it is, there will be a record in _blockLengths indicating how many instructions the basic block represented by this entry point has.
Then we can simply scan from the beginning to the end of the method body to obtain the two pieces of information mentioned above.
privatevoidAnalyzeEntrys() { _isEntrys = newbool[_instructions.Count]; _isEntrys[0] = true; for (int i = 0; i < _instructions.Count; i++) { Instruction instruction;
instruction = _instructions[i]; switch (instruction.OpCode.FlowControl) { case FlowControl.Branch: case FlowControl.Cond_Branch: case FlowControl.Return: case FlowControl.Throw: if (i + 1 != _instructions.Count) // If the current instruction is not the last one, then the next instruction is a new entry point. _isEntrys[i + 1] = true; if (instruction.OpCode.OperandType == OperandType.InlineBrTarget) // brX _isEntrys[_instructionDictionary[(Instruction)instruction.Operand]] = true; elseif (instruction.OpCode.OperandType == OperandType.InlineSwitch) // switch foreach (Instruction target in (IEnumerable<Instruction>)instruction.Operand) _isEntrys[_instructionDictionary[target]] = true; break; } } foreach (ExceptionHandlerInfo exceptionHandlerInfo in _exceptionHandlerInfos) { _isEntrys[exceptionHandlerInfo.TryStartIndex] = true; if (exceptionHandlerInfo.TryEndIndex != _instructions.Count) _isEntrys[exceptionHandlerInfo.TryEndIndex] = true; // try if (exceptionHandlerInfo.FilterStartIndex != -1) _isEntrys[exceptionHandlerInfo.FilterStartIndex] = true; // filter _isEntrys[exceptionHandlerInfo.HandlerStartIndex] = true; if (exceptionHandlerInfo.HandlerEndIndex != _instructions.Count) _isEntrys[exceptionHandlerInfo.HandlerEndIndex] = true; // handler } }
Next, we need to perform DFS or BFS starting from each entry point, exclude invalid entry points through jump instructions, and create basic blocks.
DFS, which stands for Depth-First Search, has a significant drawback: if the method body is too large and there are too many jumps, it may cause stack overflow because DFS is recursive. BFS, which stands for Breadth-First Search, requires more code than DFS, but not much more. In the future, we will use recursion in many algorithms, so we choose DFS, which has less code. When we need to partition, we can create a new thread and specify a 4MB to 16MB stack, which will never overflow.
privatevoidAnalyzeReferencesAndCreateBasicBlocks(int startIndex) { if (!_isEntrys[startIndex]) thrownew InvalidOperationException("Invalid entry point");
int exitIndex; Instruction exit; int nextEntryIndex;
exitIndex = FindExitIndex(startIndex, out _blockLengths[startIndex]); _basicBlocks[startIndex] = new BasicBlock(EnumerateInstructions(startIndex, _blockLengths[startIndex])); exit = _instructions[exitIndex]; switch (exit.OpCode.FlowControl) { case FlowControl.Branch: // Referenced branching blocks nextEntryIndex = _instructionDictionary[(Instruction)exit.Operand]; if (_blockLengths[nextEntryIndex] == 0) // Unanalyzed branching blocks AnalyzeReferencesAndCreateBasicBlocks(nextEntryIndex); break; case FlowControl.Cond_Branch: // Referenced next block and branching block nextEntryIndex = exitIndex + 1; if (nextEntryIndex < _instructions.Count && _blockLengths[nextEntryIndex] == 0) // The next instruction is the entry point of the unanalyzed new block. AnalyzeReferencesAndCreateBasicBlocks(nextEntryIndex); if (exit.OpCode.OperandType == OperandType.InlineBrTarget) { // bxx nextEntryIndex = _instructionDictionary[(Instruction)exit.Operand]; if (_blockLengths[nextEntryIndex] == 0) AnalyzeReferencesAndCreateBasicBlocks(nextEntryIndex); } elseif (exit.OpCode.OperandType == OperandType.InlineSwitch) { // switch foreach (Instruction nextEntry in (IEnumerable<Instruction>)exit.Operand) { nextEntryIndex = _instructionDictionary[nextEntry]; if (_blockLengths[nextEntryIndex] == 0) AnalyzeReferencesAndCreateBasicBlocks(nextEntryIndex); } } break; case FlowControl.Call: case FlowControl.Next: // Referenced next block nextEntryIndex = exitIndex + 1; if (_blockLengths[nextEntryIndex] == 0) // We don't need to check whether it has reached the end. // If there are no instructions like ret, br, throw, etc., it means that there is something wrong with the control flow of this method body and it has reached the end of the block. AnalyzeReferencesAndCreateBasicBlocks(nextEntryIndex); break; } }
This is the core code for creating valid and used basic blocks through DFS. Of course, the basic blocks created in this way are still linear and have no information between blocks.
Then we need to add branches between these basic blocks, that is, add jump relationships between blocks (excluding containment relationships):
nextBasicBlock = null; for (int i = _basicBlocks.Length - 1; i >= 0; i--) { BasicBlock basicBlock; List<Instruction> instructions; int lastInstructionIndex; Instruction lastInstruction;
basicBlock = _basicBlocks[i]; if (basicBlock == null) continue; instructions = basicBlock.Instructions; lastInstructionIndex = instructions.Count - 1; lastInstruction = instructions[lastInstructionIndex]; switch (lastInstruction.OpCode.FlowControl) { case FlowControl.Branch: basicBlock.BranchOpcode = lastInstruction.OpCode; basicBlock.FallThrough = _basicBlocks[_instructionDictionary[(Instruction)lastInstruction.Operand]]; instructions.RemoveAt(lastInstructionIndex); break; case FlowControl.Cond_Branch: if (nextBasicBlock == null) // nextBasicBlock should not be null because we have removed invalid code before this. thrownew InvalidOperationException(); basicBlock.BranchOpcode = lastInstruction.OpCode; basicBlock.FallThrough = nextBasicBlock; if (lastInstruction.OpCode.Code == Code.Switch) { Instruction[] switchTargets;
switchTargets = (Instruction[])lastInstruction.Operand; basicBlock.SwitchTargets = new List<BasicBlock>(switchTargets.Length); for (int j = 0; j < switchTargets.Length; j++) basicBlock.SwitchTargets.Add(_basicBlocks[_instructionDictionary[switchTargets[j]]]); } else basicBlock.ConditionalTarget = _basicBlocks[_instructionDictionary[(Instruction)lastInstruction.Operand]]; instructions.RemoveAt(lastInstructionIndex); break; case FlowControl.Call: case FlowControl.Next: if (nextBasicBlock == null) thrownew InvalidOperationException(); basicBlock.BranchOpcode = OpCodes.Br; basicBlock.FallThrough = nextBasicBlock; break; case FlowControl.Return: case FlowControl.Throw: basicBlock.BranchOpcode = lastInstruction.OpCode; instructions.RemoveAt(lastInstructionIndex); break; } nextBasicBlock = basicBlock; } }
Handle some simple cases, which may not need to be converted into a tree structure, that is, there is no need to add containment relationships between basic blocks. However, in most cases, we need to convert them into a tree structure (the MethodBlock we defined earlier).
The relationship between blocks only depends on exception handling clauses. We only need to merge the basic blocks included in the try/catch together.
Before this, we need to define a new exception handling clause structure. We can mark the first basic block in the try scope, which is the entry point of the try, indicating that there is an exception handling clause here. Because on the same entry point, there may be multiple handlers in a try block, such as:
Taking these situations into consideration, our structure can be defined as follows. Of course, this definition is not set in stone and can be modified to suit individual preferences. I prefer this definition because I find it more convenient. If you have a more convenient structure, feel free to define it in your own way as long as the final objective is achieved.
public List<LinkedExceptionHandlerInfo> Children { get { if (_children == null) _children = new List<LinkedExceptionHandlerInfo>(); return _children; } } }
Next, we need to analyze the relationships between the exception handling clauses and save them in the structure we just defined.
We add a dummy exception handling clause called “dummy”. The parent of the dummy clause is any other exception handling clause. This will facilitate recursive operations to merge all blocks in a scope into a single scope.
if (!exceptionHandlerInfo.IsVisited) { Debug.Assert(false); // Normally, we should not encounter invalid exception handling information, and currently no obfuscators add such information. continue; } scope = _linkedExceptionHandlerInfoRoot.FindParent(exceptionHandlerInfo, out isTryEqual); if (isTryEqual) scope.Handlers.Add(exceptionHandlerInfo); else { List<LinkedExceptionHandlerInfo> children; LinkedExceptionHandlerInfo child;
children = scope.Children; child = new LinkedExceptionHandlerInfo(exceptionHandlerInfo); if (!scope.HasChildren) children.Add(child); else { int subChildCount;
subChildCount = 0; for (int i = 0; i < children.Count; i++) { LinkedExceptionHandlerInfo subChild;
subChild = children[i]; // We check whether a child is a scope of a subChild. if (child.TryInfo.HasChild(subChild.TryInfo)) { child.Children.Add(subChild); subChildCount++; } else // We move the subChild forward. children[i - subChildCount] = subChild; } children.RemoveRange(children.Count - subChildCount, subChildCount); children.Add(child); } } } }
Do you remember the interface IBlock that we declared earlier? All block structures must inherit from IBlock to indicate that they are blocks.
We add a field called “_blocks” to represent an array of this interface.
if (linkedExceptionHandlerInfo.HasChildren) // Find the smallest exception handling block. foreach (LinkedExceptionHandlerInfo child in linkedExceptionHandlerInfo.Children) CombineExceptionHandlers(child); tryInfo = linkedExceptionHandlerInfo.TryInfo; tryBlock = new TryBlock(EnumerateNonNullBlocks(tryInfo.TryStartIndex, tryInfo.TryEndIndex)); RemoveBlocks(tryInfo.TryStartIndex, tryInfo.TryEndIndex); _blocks[tryInfo.TryStartIndex] = tryBlock; // try foreach (ExceptionHandlerInfo handlerInfo in linkedExceptionHandlerInfo.Handlers) { AddHandler(tryBlock, handlerInfo); RemoveBlocks(handlerInfo.FilterStartIndex == -1 ? handlerInfo.HandlerStartIndex : handlerInfo.FilterStartIndex, handlerInfo.HandlerEndIndex); } // filter/handler }
This way, we obtain the inclusion relationship between blocks and a complete tree structure. Next, we remove the null values from the _blocks array, and we have a MethodBlock.
Displaying Blocks in Text Format
Code is never free of bugs when first written and debugging is necessary before the code can be bug-free. Control flow is an abstract concept, without special treatment, you cannot see branches or where they lead like you would when observing a river’s flow. The simplest solution is to convert it to a string for display purposes.
We first add a helper class called BlockEnumerator, which can help us traverse all blocks contained in an IBlock.
We inherit from this class and write a class called BlockPrinter, overriding the virtual function OnXXBlockXX in the base class. For example, when encountering a basic block, we can do this:
Other types of IBlock are handled similarly, and their code is not included here but can be found in the attachment.
Blocks to Instruction Stream
Converting instruction stream to blocks is a complex process, but converting blocks back to instruction stream is much simpler.
First, we need to convert the tree-like structure of blocks back into a linear array of basic blocks. This step is the exact opposite of one step in “instruction stream to blocks” process.
After converting to basic blocks, we can more conveniently generate jump statements and exception handling clauses in the metadata.
We start by adding a class called BlockInfo, whose instances will be added as additional data to each basic block.
If a basic block is an entry point for an exception handling clause, then the _tryBlocks property of its BlockInfo will not be null. We can use this additional information to generate exception handling clauses.
public Instruction BranchInstruction => _branchInstruction;
public List<TryBlock> TryBlocks => _tryBlocks;
///<summary> /// Indicates whether the current block can be skipped (the current block must have only one br instruction, and the target of br is the next basic block) ///</summary> publicbool CanSkip { get => _canSkip; set => _canSkip = value; } }
We also add a class called BlockLayouter. This class can convert MethodBlock into a collection of many basic blocks and add additional data to the basic blocks.
switchTargets = new Instruction[basicBlock.SwitchTargets.Count]; for (int i = 0; i < switchTargets.Length; i++) switchTargets[i] = GetFirstInstruction(basicBlock.SwitchTargets[i]); branchInstruction.Operand = switchTargets; } else branchInstruction.Operand = GetFirstInstruction(basicBlock.ConditionalTarget); } // Add jump instructions for (int i = 0; i < _basicBlocks.Count; i++) { BasicBlock basicBlock; BlockInfo blockInfo; Instruction branchInstruction; BasicBlock nextBasicBlock;
basicBlock = _basicBlocks[i]; blockInfo = basicBlock.PeekExtraData<BlockInfo>(); if (blockInfo.CanSkip) continue; branchInstruction = blockInfo.BranchInstruction; nextBasicBlock = i + 1 == _basicBlocks.Count ? null : _basicBlocks[i + 1]; if (branchInstruction.OpCode.Code == Code.Br) { AppendInstructions(basicBlock, basicBlock.FallThrough == nextBasicBlock); // Unconditional jump instruction, if the target block is the next block, we can omit the branch instruction. } elseif (branchInstruction.OpCode.FlowControl == FlowControl.Cond_Branch) { AppendInstructions(basicBlock, false); if (basicBlock.FallThrough != nextBasicBlock) // Jump repairs are necessary. _instructions.Add(new Instruction(OpCodes.Br, GetFirstInstruction(basicBlock.FallThrough))); } else AppendInstructions(basicBlock, false);
} }
privatevoidAppendInstructions(BasicBlock basicBlock, bool canSkipBranchInstruction) { if (!basicBlock.IsEmpty) _instructions.AddRange(basicBlock.Instructions); if (!canSkipBranchInstruction) _instructions.Add(basicBlock.PeekExtraData<BlockInfo>().BranchInstruction); }
In the code, CanSkip represents whether the block is a basic block with only a br instruction and no other instructions, and the target of the br is the next basic block. If it is, this basic block can be omitted completely. If the jump instruction of a basic block is br and the target is the next basic block, then we only need to add the other instructions of this basic block and do not need to add a jump instruction.
Next is generating exception handling clauses. The core code is as follows:
privatevoidGenerateExceptionHandlers() { _exceptionHandlers = new List<ExceptionHandler>(); for (int i = _basicBlocks.Count - 1; i >= 0; i--) { // Innermost exception blocks should be declared first. (Error: 0x801318A4). // So, we traverse it in reverse order. BasicBlock basicBlock; List<TryBlock> tryBlocks;
There is also a list of local variables used in generation, which is not included here. In fact, my code for generating local variables may be a bit cumbersome. It would be much simpler to directly iterate through all basic blocks and add the first encountered local variable to the list. The whole project is already packaged, so I’m too lazy to change it.
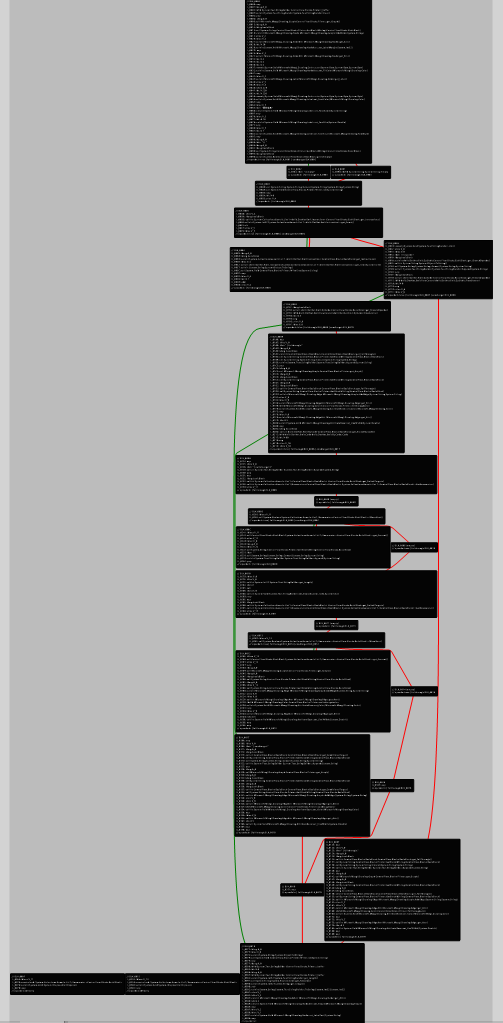
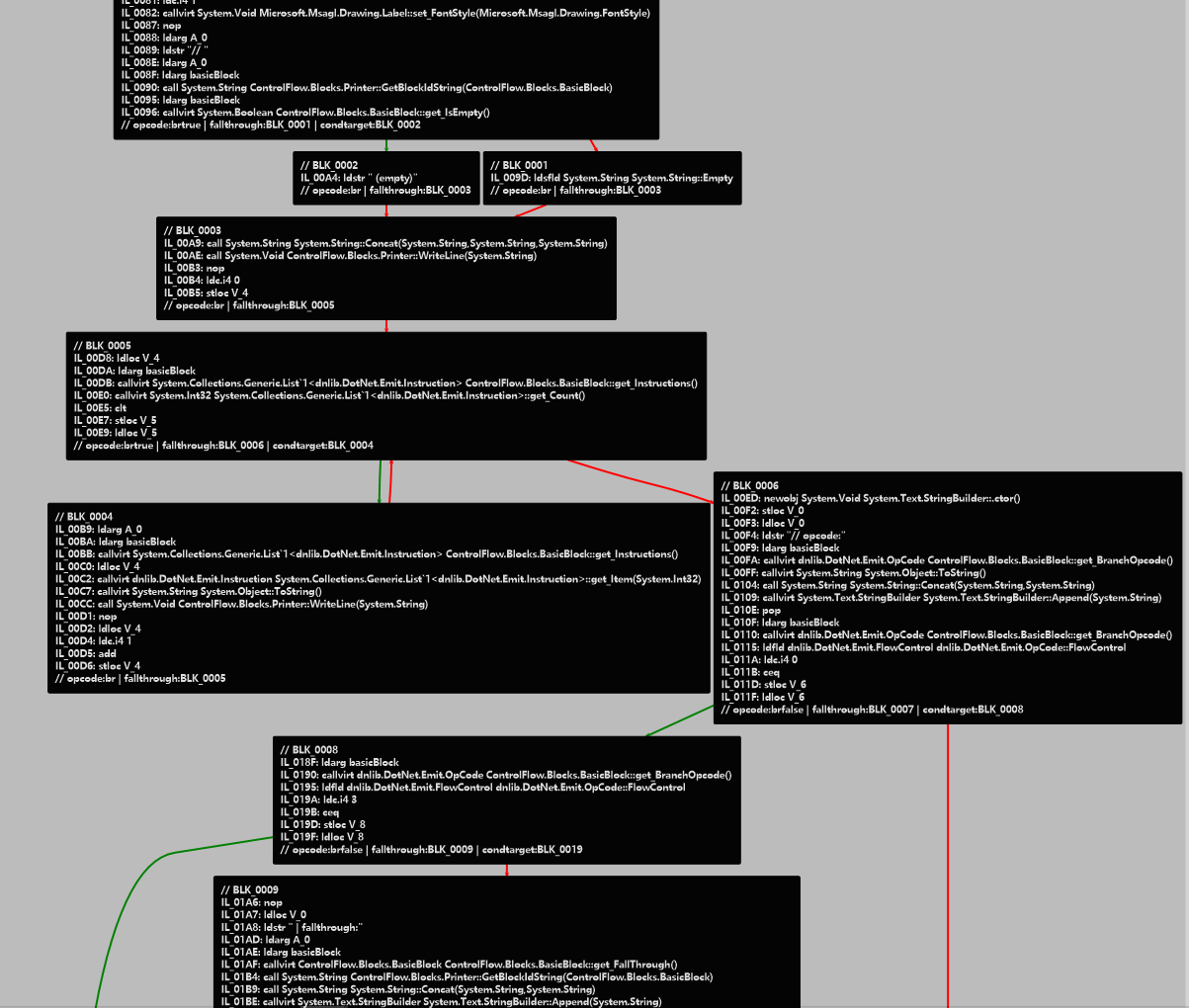
Drawing Control Flow
This is a new section that I added. I also learned how to draw control flow diagrams this morning, so I will just paste the resulting image here. However, this control flow diagram does not seem to show the relationship between exception handling blocks.
The red lines represent unconditional jumps, while the green lines represent conditional jumps.